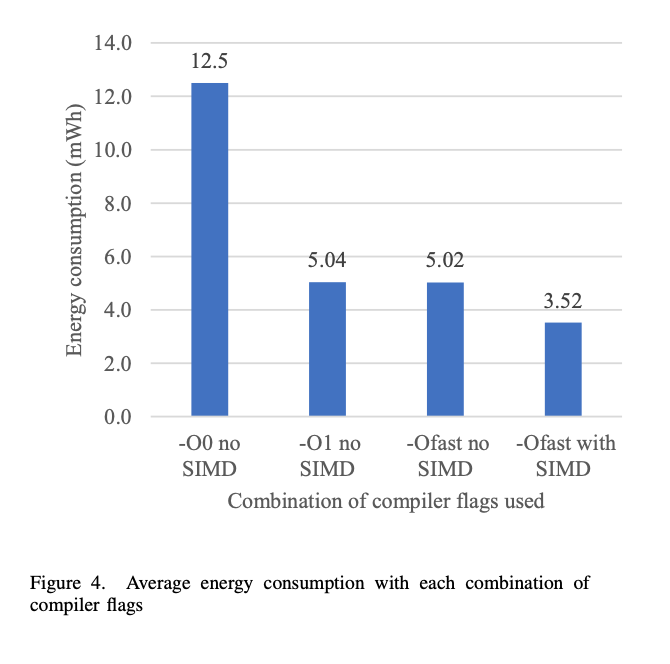
2020
Dylan Hayton-Ruffner
Word Embedding Driven Concept Detection in Philosophical Corpora
Advisor: Fernando Nascimento
During the course of research, scholars often explore large textual databases for segments of text relevant to their conceptual analyses. This study proposes, develops and evaluates two algorithms for automated concept de- tection in theoretical corpora: ACS and WMD Retrieval. Both novel algorithms are compared to key word search, using a test set from the Digital Ricoeur corpus tagged by scholarly experts. WMD Retrieval outperforms key word search on the concept detection task. Thus, WMD Retrieval is a promising tool for concept detection and information retrieval systems focused on theoretical corpora.
Dani Paul Hove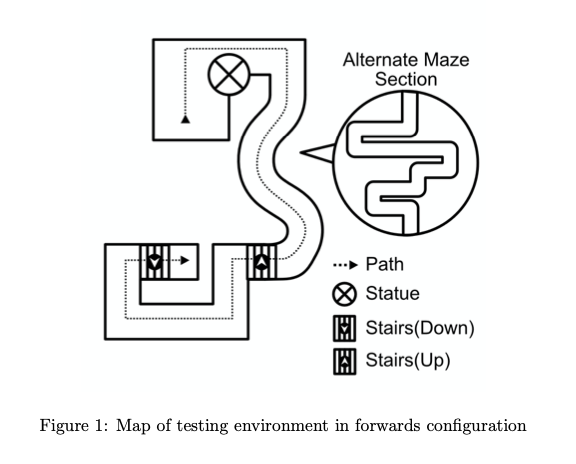
Virtual Reality Accessibility with Predictive Trails
Advisor: Sarah Harmon
Comfortable locomotion in VR is an evolving problem. Given the high probability of vestibular-visual disconnect, and subsequent simulator sickness, new users face an uphill battle in adjusting to the technology. While natural locomotion offers the least chance of simulator sickness, the space, economic and accessibility barriers to it limit its effectiveness for a wider audience. Software-enabled locomotion circumvents much of these barriers, but has the greatest need for simulator sickness mitigation. This is especially true for standing VR experiences, where sex-biased differences in mitigation effectiveness are amplified (postural instability due to vection disproportionately affects women).
Predictive trails were developed as a shareable Unity module in order to combat some of the gaps in current mitigation methods. Predictive trails use navigation meshes and path finding to plot the user’s available path according to their direction of vection. Some of the more prominent software methods each face distinct problems. Vignetting, while largely effective, restricts user field-of-vision (FoV), which in prolonged scenarios, has been shown to disproportionately lower women’s navigational ability. Virtual noses, while effective without introducing FoV restrictions, requires commercial licensing for use.
Early testing of predictive trails proved effective on the principal investigator, but a wider user study - while approved - was unable to be carried out due to circumstances of the global health crisis. While the user study was planned around a seated experience, further study is required into the respective sex-biased effect on a standing VR experience. Additional investigation into performance is also required.
Luca Ostertag-Hill
Ideal Point Models with Social Interactions Applied to Spheres of Legislation
Advisor: Mohammad Irfan
We apply a recent game-theoretic model of joint action prediction to the congressional setting. The model, known as the ideal point model with social interactions, has been shown to be effective in modeling the strategic interactions of Senators. In this project, we apply the ideal point models with social interactions to different spheres of legislation. We first use a machine learning algorithm to learn ideal point models with social interactions for individual spheres using congressional roll call data and subject codes of bills. After that, for a given polarity value of a bill, we compute the set of Nash equilibria. We use the set of Nash equilibria predictions to compute a set of most influential senators. Our analysis is based on these three components--the learned models, the sets of Nash equilibria, and the sets of most influential senators. We systematically study how the ideal points of senators change based on the spheres of legislation. We also study how most influential senators, that is a group of senators that can influence others to achieve a desirable outcome, change depending on the polarity of the desirable outcome as well as the spheres of legislation. Furthermore, we take a closer look at the intra-party and inter-party interactions for different spheres of legislation and how these interactions change depending on whether or not we model the contextual parameters. Finally, we show how probabilistic graphical models can be used to extend the computational framework.
 Darien Gillespie
Darien Gillespie Cassandra Goldberg
Cassandra Goldberg Leopold Spieler
Leopold Spieler Lily Smith
Lily Smith  Angus Zuklie
Angus Zuklie Stephen Crawford
Stephen Crawford