In this project you will start working with TIGER/Line data (TIGER = Topologically Integrated Geographic Encoding and Referencing system). This represents a database of line segments covering
Read carefully the File Overview section then scroll down to the end of the page and download data for your desired state. If you click on Maine, for instance, you will see a list of all counties in Maine and a zip file containing data for each county. You will need to download all these data, collect it into a directory, unzip it, etc.
To understand the file structure and data format you will need to read the documentation:
Please try to avoid printing as much as possible --- the full document has 346 pages!
To get started, take a look at the associated FIPS codes for state and counties, given in Appendix A. For Maine, the state code is 23, and the counties codes are as follows:

Note that for each county in Maine there is a corresponding .zip data file. For instance, tgr23005.zip contains TIGER/Line data for Cumberlands county.
All spatial objects in the TIGER/Line files exist in a single data layer that includes roads, hydrography, railroads, boundary lines and miscellanous features. All these are topologically linked and create a topologically consistent network.
The information about spatial objects is organized in records files. The 2003 TIGER/Line data consists of 19 record types that collectively contain attributes like address ranges and ZIP codes, street names, classification codes, latitude and longitude coordinates and so on.
Each county file will expand into a folder containing up to 19 files, each file corresponding to a record type (The file extension will tell you the record type). Some counties do not require all of the 19 record types and will have less than 19 files. For instance, the data for Cumberlands county looks like this:
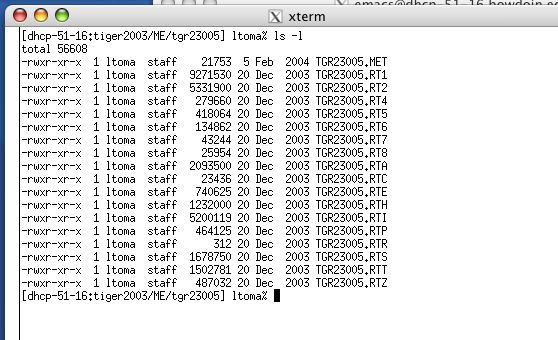
The file TGR23005.RT1 contains record-type-1 data, TGR23005.RT2 contains record-type-2 data, and so on.
Users of TIGER/Line files need to link information from several record types to find all attributes of interest that belong to one spatial object. For instance, RT1 contains address ranges and ZIP codes, RT2 contains latitude and longitude coordinate values for all points on a chain (road) that is not a straight line, RT7 described landmark features, and so on. For an overview of the record types and what information they contain read Chapter 1 in the Technical Documentation [PDF].
For this project, you will need to work with records/files RT1 and RT2. Together they describe chains (roads). Each chain has an unique ID and may be a straight line or may have several points in between (polyline). You can read a documentation of these in the technical documentation at page 1-10 (page 37 in pdf viewer).
The start and end points of a chain are called nodes. The intermediate points on a chain are called shape points. Remember, all chains are topologically linked and create a topologically consistent network. That is, any intersection of two segments, of whatever type, is marked with a node.
Record Type 1 contains a single record for each unique chain. Each record contains the chain ID (TLID), the feature type (road, hydrography, railroad, etc), the coordinates of the start and end nodes of the chain, and others.
Record Type 2 gives the coordinates of the intermediate points (the shape points) on the chains referenced by the feature ID given in Record Type 1.
The feature type in RT1 is encoded as a Census Feature Class Code (CFCC). CFCCs are described in Chapter 3, starting at pages 3-26 :3-42 (pages 81:97 in pdf). The CFCC is a three digit code. The first digit is a letter that represents the major type: A for roads, B for railroad, C for pipeline,..., H for hydrography. The following two digits are numbers, describing further the feature type. CFCC A11, for instance, means primary road, A34 secondary road, and so on. Thus, all roads beging with letter A, railroads beging with letter B, and so on.
More detailed information about chains and record types 1 and 2 is found on pages 3-42: 3-44 in the documentation (97:99 in pdf). On page 3-44 it is pointed out that "Plotting a complete chain requires using the nodes from Record Type 1, and all of the shape points records in Record Type 2 with the same TLID, if any. Plot the start node first, then search RT2 for any matching records, and ...finally plotting the end node from RT1.
Now to see the exact formatting of RT1 and RT2, refer to the data record formats in Chapter 6, pages 6-1: 6-3 (186-189 in pdf). To extract just road data you would pay attention to the following fields/offsets:
In Record Type 1:
field name, offset start-end, length, decription TLID, 6, 15, 10 Tiger/LINE ID CFCC, 56,58, 3 Census Feature Class Code ... FRLONG, 191,200, 10, Start Longitude FRLAT, 201,209, 9, Start Latitude TOLONG, 210, 219,10, End Longitude TOLAT , 220,228 9, End Latitude
In Record Type 2:
field name, offset start-end, length, decription TLID , 6, 15, 10, Tiger/LINE ID RTSQ , 16, 18, 3, Record Sequence Number LONG1, 19, 28, 10, Point 1 Long. LAT1 , 29, 37, 9, Point 1 Lat LONG2, 38, 47, 10, Point 2 Long. LAT2 , 48, 56, 9, Point 2 Lat. ....
The records are in ASCII, so you can just open up the RT1 file and RT2 file and see some examples. For instance, open up TGR23005.RT1 and go to line 184.
11103 78067476 N Farley Rd A41 198 2 199 100000401104011 23230050050843008430 083950839501110001110010381033 -69915326+43909467 -69907481+43910243You can go to the various offsets and see that the following attributes:
TLID= 78067476 CFCC=A41 (Local, neighborhood, and rural road, city street, unseparated) FRLONG=-69915326 (69.915326 degrees West) FRLAT=+43909467 (43.909467 degrees North) TOLONG=-69907481 TOLAT=+43910243 ...To read about coordinates of node and shape points go to page 3-42 (97 in pdf).
Then open file TGR23005.RT2 and search for TLID= 78067476 to find the intermediate points. You will find this line:
21103 78067476 1 -69915325+43909455 -69915324+43909428 -69915294+43908735-69915010+43908575 -69914599+43908598 -69914061+43908826 -69912890+43909786-69912511+43909764 -69911815+43909283 -69910866+43909283The first coordinate in this list corresponds to the first shape point in the chain, which is:
LONG1=-69915325 LAT1=+43909455...and so on. The last two fields in this line are non-zero
LONG10=-69910866 LAT10=+43909283meaning that this (chain) road is further continued in the next entry. Note that the first entry in the RT2 file has a RTSQ=1 indicating this is the first set of intermediate coordinates. The next entry has has also TLID= 78067476, but RTSQ=2, and gives the remaining coordinates in the chain. There are only two more
LONG1=-69909316 LAT1=+43909763 LONG2=-69908051 LAT2=+43910037The remaining entries are all zeros.
So, if you wanted the chain for this whole road, you would start with the start node in RT1
FRLONG=-69915326 (69.915326 degrees West) FRLAT=+43909467 (43.909467 degrees North)Sequentially list the points with the matching TLID and RTSQ=1 from the RT2 file
LONG1=-69915325 LAT1=+43909455 ... LONG10=-69910866 LAT10=+43909283Continue with remaining points in the next RT2 entry with RTSQ=2
LONG1=-69909316 LAT1=+43909763 LONG2=-69908051 LAT2=+43910037And finish with the end node from RT1
TOLONG=-69907481 TOLAT=+43910243So it is a bit complicated....but, you can easily (don't you love it when people say easily?) extract the fields from RT1 and RT2 files for each county.
OK...now coming back to the project: display in OpenGL the roads, railroads, and hydrography in an entire state in the U.S. of your choice.
475648756 3 x1 y1 x2 y2 x3 y3 398568569 5 x1 y1 x2 y2 ...This says that chain with TLID=475648756 has 3 points etc. In order that we are able to check for consistency, I ask that you save the chain in order of TLID.
Some questions before you start:
For instance, you could start by ignoring RT2 and displaying each chain as a segment between the two endpoints using only the info in RT1. Then add the intermediate shape points from RT2.
Also, if you were thinking of building an index, refrain from doing it from the beginning, wait until you have something that works, even though slow, and add the index afterwards.
We (that is, you) will build on this project further in the comings weeks, so code neatly, and...think before you start!
The file format for RT1 and RT2 records has (probably) not changed that much over the years, so the fields are likely the same for other version of TIGER/Line. The offsets might be a bit different though. If you work with 2004 data, be careful!
Start early, don't procrastinate. Good luck!