CS 210 - Lab 9: Modeling the Student Registration Process
Part 1 due December 9, 1998
Part 2 due December 16, 1998
General Lab Goals
This lab provides an opportunity for the class to collaboratively design
and implement a significant piece of software that can register students
in a complete semester 's worth of courses at Bowdoin. This exercise provides
an opportunity to design a significant computing application using C++
and the data structures we have studied in this course. The data we will
use in this lab is actual Bowdoin registration and course data for the
Spring 1998 semester.
This project will serve as the final exam for the course. It has a collaborative
part and an individual part, which are explained below. All software and
data files for this lab are in the CS210 (Chown) -> Lab 9 folder.
Overview:
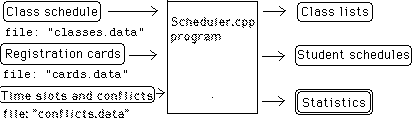
The picture in Figure 1 provides an overview of the registration process.
The "Scheduler.cpp" program has three major input files; the class schedule,
the students' registration cards, and a file listing time slots and conflicts.
The output of the program would, in practice, have three major parts; class
lists (which are distributed to instructors), student schedules (which
are distributed to students), and printed statistics which summarize the
results of the scheduling process. For the purposes of this exercise, we
will skip the generation of class lists and student schedules, focussing
instead on the registering of students in courses and the generation of
enrollment statistics, as explained below.
The files classes.data and cards.data represent the
actual input to the Spring 1998 registration process; they are provided
in the Lab 10 folder for your use.
The file classes.data contains one line of text for each course
section offered in Spring 1998. For simplicity, this file excludes lab
sections. A sample of the first few lines in this file is shown in Figure
1.
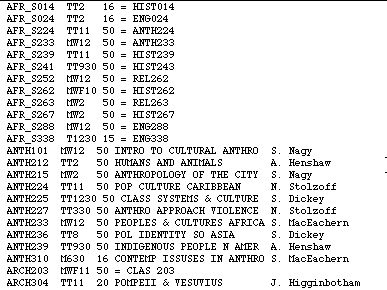
Figure 1. First few lines of the "classes.data" file
Each line in this file contains information about a specific course --
its department, course number, scheduled meeting time, and capacity (maximum
enrollment). Some lines continue with an equals sign (=) and another course
number, indicating a course with which this course is cross-listed. The
other (non-cross-listed) lines contain the course title and the name of
the instructor.
Below is the beginning of a class definition for a single course in
this file.

The file cards.data contains the information that students
fill in on their registration cards. It has one line of text for each student
who is registering for courses in Spring 1998. For simplicity, it also
excludes lab preferences. A sample of the first few lines in this file
is shown in Figure 2.

Figure 2. First few lines of the "cards.data" file.
Each line in this file contains information about a specific student --
a student id number, class, number of courses desired, total number of
courses listed, and the course numbers of all the courses listed (in order
of preference, reading left-to-right across the first line of the registration
card, then the second, and then the third). For example, the first line
shows that student #1, class of '90, wanted four courses and listed 6 courses
on the card. That student's first line of choices are CHEM 226A, ES 216,
BIO 272, and SOC 215; courses ES 391 and BIO 214 were listed as alternates
on the second line.
Below is the beginning of a class definition of the Student class that
can be used to read lines from this file. The names of the fields in this
class correspond with the information on each line of Figure 2, from left
to right. Since a student can list a variable number of course choices,
these are defined below as an array of Strings.

In solving this problem, it is important to think about the basic algorithm
for determining how courses are selected for a student. That is, each course
listed in the student_choices array must be searched in a data
structure that contains the information about all courses (that data structure
should be loaded from the file classes.data before this algorithm
can begin). Once that course is found, two criteria must be met before
that student can be enrolled in that class:
-
That course must not be full to capacity (that is, the field enrollment,
which keeps track of the number of students already enrolled in that course,
must be updated each time a new student is added to the course), and
-
That course's meeting time must not be in conflict with the meeting time
of any course in which the student is already enrolled.
The first criterion is easy to check. The second criterion can be checked
by keeping a list of all the possible meeting times, and along with each
one a list of all times that are in conflict with that time. Below is a
partial list of these meeting times and their respective conflicting times;
their interpretation should be self-explanatory.
A complete list of all class meeting times alongside all conflicting
times, is given in the file conflicts.data. Below is a list of
the first few lines in that file. Here, the first line says that the time
MWF8 conflicts with the time M-F8, while the third line says that MWF9
conflicts with each of the three times MW915, MW9, and MW930.

Finally, the program should produce an output that has the information
shown below.
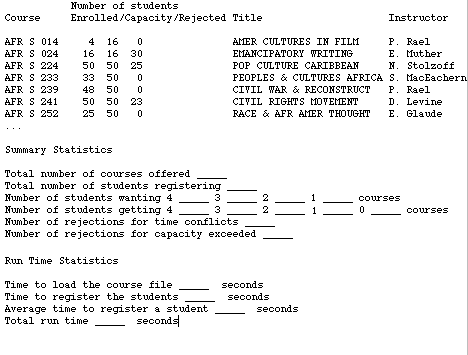
In addition to the summary enrollment data for each course, the program
should keep track of and display additional "Summary Statistics" and "Run
Time Statistics."
The summary statistics reveal how many students did and did not get
their desired number of courses, the number of times students were rejected
from courses for time conflicts, and the number of times students were
rejected from courses because the course was full.
The run time statistics reveal how much time it took to run the two
major parts of your program, the loading of the class data structure and
the registering of students. These numbers, of course, will vary depending
on your choice of data structure and search strategy for registering students.
To assist you with this task, the skeleton program Register.cpp
is provided in the Lab 9 folder. It simply reads records from the
classes.data file into a Vector (an enhanced Array type), and
then reads individual student records one-by-one. It contains the beginnings
of a class definition for a student (called Student) and a course
(called Course).
To exercise this program, you may set up a project that looks like this:
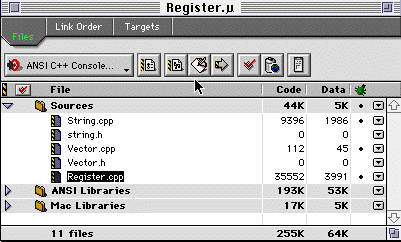
Now drag the files "classes.data," "cards.data," "conflicts.data," and
"Register.cpp" into this project's folder, and then Make and Run
it. Its output should be similar to that shown in Figures 1 and 2.
Major Lab Tasks
The work for this lab can be divided into several major tasks.
-
Designing an efficient data structure for storing the classes.data
file (a Vector may be the worst possible choice), and flushing out the
overall structure of the program.
-
The data structure choices here are Vector, Binary SearchTree, AVL Tree,
and HashTable.
-
Each choice presents performance tradeoffs for adding elements during the
building phase and searching the data structure to find elements during
the registration process.
-
Remember, to register 1400 students with 4 choices per student requires
5600 separate searches in this data structure!
-
Develop working implementations of each data structure using a common interface
so that your program can easily switch between them. When you are
done you will need to choose one for the final version and provide an explanation
for your choice.
-
Addition of appropriate variables and calls to track the run time statistics
for the two major parts of the program (see additional suggestions commented
into the sample Register.cpp program).
-
Determining, for a given student and course, whether that course's time
is in conflict with any other courses which the student has been assigned
so far.
-
Registering a single student with the number of courses he/she desires.
-
Keeping track of the appropriate summary statistics
-
Displaying the registration results, summary statistics, and run time statistics
after all the student cards have been processed.
Part 1 Outcome (As a Team): a complete, correctly-running, and well-documented
C++ program for this problem. Teams should prepare to demonstrate their
results on December 9 at 2:00 (that is the time of the last lab of the
course).
Part 2 Outcome (Individually): the following written work, which
is due on December 16 at 5pm:
-
A brief description of your overall role in the project, including what
you contributed, what help you gave or received from other team members.
-
A complete listing of the program that your team developed, with the parts
you developed circled.
-
A discussion of which data structure your team settled upon and why you
made that choice.
-
A calculation of the theoretical complexity of this program, taking into
account all data structures used, methods called, and the number of steps
required to run each part of the program. You should develop this calculation
by identifying how various relevant parts of the text of the program contribute
to its complexity. The final expression should be written in the form O(t),
where involves at least the following variables:
-
the number of students ns, in the students.data file,
-
the number of courses nc, in the courses.data file, and
-
the (worst-case) number of possible conflicts nf that can occur
for registering each student.
Organization:
This is a team project . The teams are identified below. Team captains
are indicated with asterisks (*), and will assign tasks and oversee the
completion of Part 1.
Team A: *Doug Vail, Kim Schneider, Henry Chance, Thurston Riday
Team B: *Adam Greene, Megan Wardrop, Wasif Khan, Rob Ford
Team C: *Curtis Jirsa, Ben Oyer, Brian Haley, Jon Lapak
There's a modest amount of competition involved here, since each team
will want to design the most efficiently-running registration program.
Other qualities, like program organization and clarity, robustness, and
effective use of C++ classes and data structures concepts, will also be
important in the final design. Run-time efficiency, of course, depends
critically on your choice of data structures.