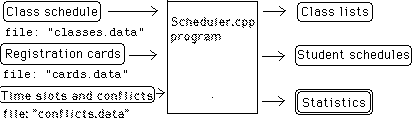
This project will serve as the final exam for the course. It has a collaborative part and an individual part, which are explained below. All software and data files for this lab will be in the course folder.
The files classes.data and cards.data represent the actual input to the Spring 1998 registration process; they are provided in the folder for your use.
The file classes.data contains one line of text for each course section offered in Spring 1998. For simplicity, this file excludes lab sections. A sample of the first few lines in this file is shown in Figure 1.
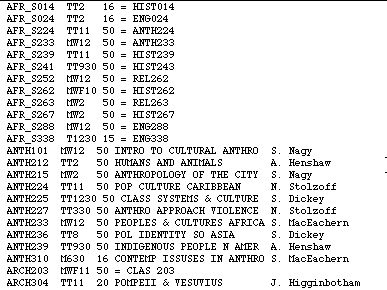
Below is the beginning of a class definition for a single course in this file.

The file cards.data contains the information that students fill in on their registration cards. It has one line of text for each student who is registering for courses in Spring 1998. For simplicity, it also excludes lab preferences. A sample of the first few lines in this file is shown in Figure 2.

Below is the beginning of a class definition of the Student class that can be used to read lines from this file. The names of the fields in this class correspond with the information on each line of Figure 2, from left to right. Since a student can list a variable number of course choices, these are defined below as an array of Strings.

In solving this problem, it is important to think about the basic algorithm for determining how courses are selected for a student. That is, each course listed in the student_choices array must be searched in a data structure that contains the information about all courses (that data structure should be loaded from the file classes.data before this algorithm can begin). Once that course is found, two criteria must be met before that student can be enrolled in that class:
A complete list of all class meeting times alongside all conflicting times, is given in the file conflicts.data. Below is a list of the first few lines in that file. Here, the first line says that the time MWF8 conflicts with the time M-F8, while the third line says that MWF9 conflicts with each of the three times MW915, MW9, and MW930.

Finally, the program should produce an output that has the information shown below.
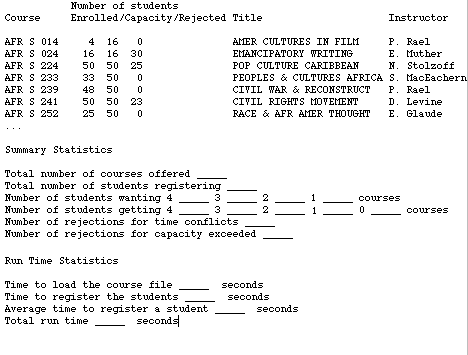
In addition to the summary enrollment data for each course, the program should keep track of and display additional "Summary Statistics" and "Run Time Statistics."
The summary statistics reveal how many students did and did not get their desired number of courses, the number of times students were rejected from courses for time conflicts, and the number of times students were rejected from courses because the course was full.
The run time statistics reveal how much time it took to run the two major parts of your program, the loading of the class data structure and the registering of students. These numbers, of course, will vary depending on your choice of data structure and search strategy for registering students.
To assist you with this task, the skeleton program Register.cpp
has already been provided. It simply reads records from the classes.data
file into a Vector (an enhanced Array type), and then reads individual
student records one-by-one. It contains the beginnings of a class definition
for a student (called Student) and a course (called Course).
You should already have some experience working with this from last week's
class.
Suggestion: Tackle this part of the project one piece at a time. You should have already begun working on the Hash Table. Finish that first. Then work on reading in the conflicts. First just get the program to read them into a simple data structure (like an array). Once you can do that, then work on your Binary Tree. I will not help you debug one part of the program until you can prove to me that the previous parts of the program already work.
What to hand in: Hardcopy of your code and a listing of all the potential course conflicts. A simple format for this would be the student number followed by the names of the potentially conflicting courses. As usual, place copies of your code (appropriately named) in the drop box.
Part 2 : The final data structure you design should hold student information. The basic registration algorithm will proceed in a fashion similar to the algorithm you used in Lab 6. Essentially you will make multiple passes on all of the students, first scheduling all of the student's first choices, then all of their second choices, etc. Your data structure will need to hold all of the student information and access them giving first priority to seniors, second to juniors, etc. Within a class you may break ties arbitrarily. E.g. a senior and a junior both have the same class listed as their first priority. The senior will be able to register for the class before the junior has a chance. If two seniors have the same course, on the other hand, the first senior you process has higher priority.
Add in appropriate statistical information.
Part 3: Implement the registration algorithm described in part 2. Add in functionality to display all of the relevant statistical information.
Final: Your final (take home) will be a theoretical analysis
of the time complexity of the finished project.
Calculate the theoretical
complexity of this program, taking into account all data structures used,
methods called, and the number of steps required
to run each part of the program.
You should develop this calculation by identifying how various relevant
parts of the text of the program contribute to its
complexity. The final expression
should be written in the form O(t), where involves at least the following
variables:
the number of students ns, in the students.data file,
the number of courses nc, in the courses.data file, and
the (worst-case) number of possible conflicts nf that can occur for registering
each student.