Statistical Methods for Ambiguity Resolution
Statistical methods have been developed (E.g., Charniak, 1993) that help
select part of speech, word sense, and grammatical structure for syntactically
ambiguous sentences. Here, we explore statistical methods for part
of speech tagging and the use of probabilistic grammars in parsing.
Part of speech tagging
Statistical methods for reducing ambiguity in sentences have been developed
by using large corpora (e.g., the Brown Corpus or the COBUILD Corpus)
about word usage. The words and sentences in these corpora are pre-tagged
with the parts of speech, grammatical structure, and frequencies of usage
for words and sentences taken from a broad sample of written language. Part
of speech tagging is the process of selecting the most likely part of
speech from among the alternatives for each word in a sentence. In practice,
only about 10% of the distinct words in a million-word cprpus have two or
more parts of speech, as illustrated by the following summary for the complete
Brown Corpus (DeRose 1988):
Number
of Tags |
Number of
distinct words |
Percent
of total |
| 1 |
35,340 |
89.6% |
| 2 |
3,760 |
9.5 |
| 3 |
264 |
0.6 |
| 4 |
61 |
0.1 |
| 5 |
12 |
0.03 |
| 6 |
2 |
0.005 |
| 7 |
1 |
0.0025 |
| Total 2-7 |
4,100 |
10.4% |
The one word in the Brown corpus that has 7 different part of speech tags
is "still." Presumably, those tags include at least n, v,
adj, adv, and conj. In practice, there are a
small number of different sets of tags (or "tagsets") in use today.
For example, the tagset used by the Brown corpus has 87 different tags.
In the following discussion, we shall use a very small 4-tag set, {n,
v, det, prep} in order to maintain clarity of the ideas
behind the statistical approach to part of speech tagging.
Given n or v as the two part of speech tags (T),
for the word W = flies, the outcome is partially governed by looking
at the probability of each choice, based on the frequency of occurrence of
the given word in a large corpus of representative text.
Compare prob(T = v | W = flies), which reads "the probability
of a verb (v) choice, given that the word is "flies," with prob(T
= n | W = flies).
In statistics, the following is true for two independent events X and
Y:
prob(X | Y) = prob(X & Y) / prob(Y).
That is, the probability of event X occurring, after knowing that Y has
occurred, is the quotient of the probability of events X and Y both occurring
and the probability of Y occurring alone. Thus,
prob(T = n | W = flies) = prob(T = n & W = flies) / prob(W
= flies)
How are these probabilities estimated? The collected experience
of using these words in a large corpus of known (and pre-tagged) text, is
used as an estimator for these probabilities.
Suppose, for example, that we have a corpus of 1,273,000 words (approximately
the size of the Brown corpus) which has 1000 occurrences of the word flies,
400 pre-tagged as nouns (n) and 600 pre-tagged as verbs (v).
Then prob(W = flies), the probability that a randomly-selected word
in a new text is flies, is 1000/1,273,000 = 0.0008. Similarly,
the probability that the word is flies and it is a noun (n)
or a verb (v) can be estimated by:
prob(T = n & W = flies) = 400/1,273,000 = 0.0003
prob(T = v & W = flies) = 600/1,273,000 = 0.0005
So prob(T = v | W = flies) = prob(T = v & W = flies)
/ prob(W = flies) = 0.0005/0.0008 = 0.625. In other words, the
prediction that an arbitrary occurrence of the word flies is a verb
will be correct 62.5% of the time.
The process of part of speech tagging for an entire sentence with t
words relies not only on the relative frequencies of the sentence's words
in a pre-tagged corpus, but also on the part(s) of speech of all the other
words in the sentence. Let T1...Tn
be a series of parts of speech for an n-word sentence with words W1...Wn.
To assign the most likely parts of speech for these words using statistical
techniques, we want to find values for T1...Tn
that maximizes the following:
prob(T1...Tn | W1...Wn)
=
prob(T1...Tn) * prob(
W1...Wn | T1...Tn)
/ prob(W1...Wn)
(1)
For example, for the text "Fruit flies like a banana." we want to find part
of speech tags T1...T5 for this sequence
of n=5 words that maximizes:
prob(T1...T5
| fruit flies like a banana) =
prob(T1...T5)
* prob(fruit flies like a banana | T1...T5)
/ prob(fruit flies like a banana)
where each part of speech tag Ti comes from the set
{n, v, prep, det}.
Since this calculation would be very complex (it would require too much
data), researchers use the following (reasonably good) estimate for prob(T1...Tn
| W1...Wn), using the following approximations:
prob(T1...Tn) =
||iprob(Ti
| Ti-1)
for i=1,...,n
prob(W1...Wn | T1...Tn)
= ||iprob(Wi
| Ti)
for i=1,...,n
(Read "= ||i"
as "approximates the product over i.") This particular method of estimation
is called a bigram model, since each part of speech tag Ti
is dependent only on the previous word's part of speech choice, Ti-1.
In practice, both bigram and trigram models are used. Now, the
problem is simplified to finding a series of choices T1...Tn
that maximizes the following:
prob(T1...Tn | W1...Wn)
= ||iprob(Ti
| Ti-1) * ||iprob(Wi
| Ti) for i=1,...,n
(2)
which is a much less complex calculation than equation (1) above.
Notice here also that the denominator in (1) is dropped, since its value
would be constant over all sequences of tags T1...Tn.
For our example, we want to maximize the following:
prob(T1...T5|
fruit flies like a banana) = ||iprob(Ti| Ti-1)* ||iprob(Wi|
Ti) for i=1,...,5
= prob(T1| Ø)* prob(T2| T1)*
prob(T3| T2) * prob(T4|
T3) * prob(T5| T4) *
prob(fruit| T1) * prob(flies| T2) *
prob(like| T3) * prob(a| T4)
* prob(banana| T5)
Here, the symbol Ø denotes the beginning
of the sentence. These individual probabilities are readily computed
from the frequencies found for the pre-tagged sentences in the corpus.
That is, the probabilities prob(Ti | Ti-1)
for each adjacent pair of parts of speech choice {n, v, det,
prep}can be estimated by counting frequencies in the corpus and writing
the result in the form of a "Markov chain," such as the one shown below (adapted
from Allen, p 200):
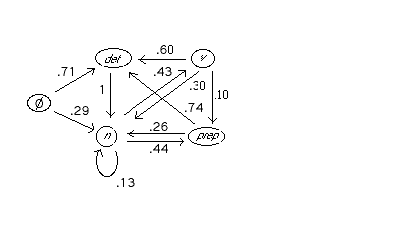
This expresses, for instance, that the probability of having a verb (v)
immediately following a noun (n) in a sentence is prob(v | n)
= 0.43. In other words, 43% of the occurrences of a noun in the
corpus are immediately followed by a verb.
With this information, we can estimate prob(n n v det n), for instance,
as:
prob(n n v det n) = prob(n | Ø) * prob(n
| n) * prob(v | n) * prob(det | v) * prob(n
| det)
= .29 * .13 * .43 * .6 * 1
= 0.00973
The corpus also provides estimates for the individual probabilites for each
word's possible part of speech. Here is some sample data derived from
a small corpus (Allen, 1995) for a few words of interest to us:
- prob(a | det) = .036
prob(a | n) = .001
prob(man | n) = .035
- prob(banana | n) = .076
prob(like | v) = .1
prob(man | v) = .007
- prob(flies | n) = .025
prob(like | prep) = .065 prob(hill | n) = .083
- prob(flies | v) = .07
prob(like | n) = .013
prob(telescope | n) = .075
- prob(fruit | n) = .061
prob(the | det) = .045 prob(on | prep)
= .09
- prob(fruit | v) = .005
prob(woman | n) = .076 prob(with | prep) = .09
Now we can use equation (2) to calculate the likelihood of the sentence
"fruit flies like a banana" being tagged with the parts of speech n n
v det n as follows:
prob(n n v det n | fruit flies like a banana)
= prob(n n v det n) * prob(fruit
| n) * prob(flies | n) * prob(like | v) * prob(a
| det) *
prob(banana
| n)
= 0.00973 * 0.061 * .025 * .1 * .036
* .076
= 0.00973
* 4.17 * 10-7
= 4.06 * 10-9
To find the most likely sequence of tags for a sentence, we need
to maximize this calculation over all possible tag sequences for the sentence.
This could be a complex computation if the "brute force" approach is used.
That is, for an n-word sentence and p parts of speech, there
are pn different taggings. Even for our small sentence
of n=5 words and p=4 different parts of speech {n, v,
det, prep}, the number of calcuations would be 45
= 1,024. However, given our particular sentence, and the fact that several
different taggings have 0 probability, there are at most 2*2*3*2*1 = 24 different
non-zero calculations, as shown below:
- fruit flies like a
banana
- n n
n det n
- v v
v n
-
prep
Moreover, this number is reduced further by the fact that some of the transitions
in the Markov chain are zero, such as prob(v | v) = 0. There
are, practically speaking, only the following 8 different taggings for our
sentence that give nonzero probabilities:
fruit flies like a banana
tagging = [n, n, n, n, n]
probability = 1.24795e-013
tagging = [n, n, v, n, n]
probability = 7.32753e-012
tagging = [n, n, v, det, n]
probability = 4.05833e-009
tagging = [n, n, prep, n, n]
probability = 4.22384e-012
tagging = [n, n, prep, det, n]
probability = 3.32909e-009
tagging = [n, v, n, n, n]
probability = 2.66722e-012
tagging = [n, v, prep, n, n]
probability = 8.89074e-012
tagging = [n, v, prep, det, n]
probability = 7.00738e-009
The probabilities calculated here are computed by the Prolog program
grammar11.pl, whose implicit nondeterminism assists in the tedious
search for alternative taggings and the accompanying calculations outlined
above. Among these, the best alternatives suggest that fruit flies
is a n n sequence or a n v sequence, leading to the following
"most probable" taggings for the entire sentence.
- prob(n n v det n | fruit flies like a banana)
- prob(n v prep det n | fruit flies like a banana)
-
Furthermore, there is an algorithm called the Viterbi algorithm, which
provides a strategy by which most of the non-zero alternatives that lead to
nonzero probabilities can also be avoided. That is, the tagging with
the maximum probability can be developed directly in a single pass on the
words in the sentence, and not require the above calculation for all the 24
combinations of part of speech taggings listed above. (For the details
of the Viterbi algorithm, see Allen, p 203).
The general results of this tagging method are quite positive (Allen
p 203): "Researchers consistently report part of speech sentence tagging
with 95% or better accuracy using trigram models."
Probabilistic grammars
Markov models can be extended to grammar rules to help govern choices among
alternatives when the sentence is syntactically ambiguous (that is, there
are two or more different parse trees for the sentence). This technique
is called probabilistic grammars.
A probabilistic grammar has a probability associated with each rule, based
on its frequency of use in the parsed version of a corpus. For example,
the following probabilistic grammar's rules have their probabilities derived
from a small corpus (Fig 7.17 in Allen).
| Grammar rule
|
prob
|
| 1. s --> np vp
|
1
|
| 2. vp --> v np pp
|
0.386
|
| 3. --> v np
|
0.393
|
| 4. --> v pp
|
0.22
|
| 5. np --> np pp
|
0.24
|
| 6. --> n n
|
0.09
|
| 7. --> n
|
0.14
|
| 8. --> det n
|
0.55
|
| 9. pp --> p np
|
1
|
For a given phrase like a banana and grammatical category (np),
we look at all the possible subtrees that can be generated for that phrase,
assigning appropriate parts of speech to the words. For example,
prob(a banana | np)
= prob(rule 8 | np)
* prob(a | det) * prob(banana | n)
+ prob(rule 6
| np) * prob(a | n) * prob(banana | n)
= .55 * .036 * .076 + .09 * .001 * .076
= 1.51*10-3
(Note that only rules 6 and 8 come into play here, since they are the
only ones that generate two-word noun phrases.) Here, we are using
the same conditional probabilities for individual words, like prob(banana
| n), that we used in the previous section for part of speech tagging.
For an entire sentence, we generate all of its possible parse trees, and
then compute the probability that each of those trees will occur, using the
above strategy. The preferred parse tree is the one whose probability
is the maximum. Consider, for example, the two parse trees for the
sentence fruit flies like a banana that are generated by the above
grammar:
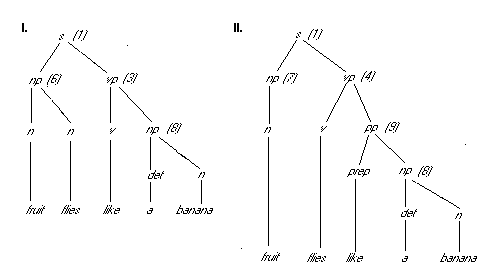
These trees are annotated with the numbers of the grammar rules that are
used at each level. Thus, to determine which is the more probable parse
for this sentence, we compute the following for each tree:
prob(fruit flies like a banana | s)
and choose the maximum value from these two computations. Here is
a summary of the necessary calculations:
- I. prob(fruit flies like a banana | s)
- = prob(rule 1 | s) *
prob(fruit flies | np) * prob(like a banana | vp)
- = 1 * prob(rule 6 | np)
* prob(fruit | n) * prob(flies | n) *
-
prob(rule 3 | vp) * prob(like | v) * prob(a banana | np)
- =
.09 * .061 * .025 * .393 * .1 * 1.51*10-3
- =
8.14 * 10-9
- II. prob(fruit flies like a banana | s)
- = prob(rule 1 | s) *
prob(fruit | np) * prob(flies like a banana | vp)
- = 1 * prob(rule 7 | np)
* prob(fruit | n) *
-
prob(rule 4 | vp) * prob(flies | v) * prob(like a banana | pp)
- = prob(rule 7 | np) *
prob(fruit | n) *
-
prob(rule 4 | vp) * prob(flies | v) * prob(rule 9 | pp) * prob(like | prep)
*
-
prob(a banana | np)
- =
.14 * .061 * .22 * .07 * 1 * .065 * 1.51*10-3
- =
12.9 * 10-9
Here, we do not show the details of the calculation of 1.51*10-3
for prob(a banana | np) that was developed above. By these calculations,
parse tree II is slightly favored over parse tree I. This result suggests
that this sentence would mean that fruit flies in the same way that a banana
flies. Adding semantic considerations, we might find that the more plausible
parse would have "fruit flies" as a noun phrase and "like" as a verb.
According to Allen and others (p 213), probabilistic parsing gives the
correct result (parse tree) about half the time, which is better than pure
guess-work but not great in general. For instance, the results we
obtained by parsing "fruit flies like a banana," from the sample grammar
and probabilities delivers the less intuitive result. Thus, we should
consider more robust approaches to semantics if we want to be able to parse
sentences like this one correctly. Statistical methods that don't take
semantic features into account have limited value in complex NLP situations.
Exercises
- Complete the calculation of prob(n v prep det n | fruit
flies like a banana), given the probabilities used in the discussion
above. What is the resulting probability? Is this greater than
that computed for prob(n n v det n | fruit flies like a banana)?
Does this result agree with your intuition about which is the more reasonable
interpretation for this ambiguous sentence?
- Revise the grammar given in the discussion above by changing the
probabilities for rules 2, 3, and 4 to .32, .33, and .35. What effect
does this change have on the selection of the best parse tree for the sentence
Fruit flies like a banana?
- Change the following probabilities in the Markov chain to the following:
- prob(n | v) = .53
- prob(det | v) = .32
- prob(prep | v) = .15
- Now recalculate the part of speech taggings for the sentence Fruit
flies like a banana. What now is the best part of speech tagging
for the words in this sentence?
- Consider the sentence The woman saw the man with the telescope.
Compute the statistically best parse for this sentence, given the two alternative
attachments of the prepositional phrase with the telescope.
- Consider the sentence The woman saw the man on the hill with the
telescope. Using the above grammar, how many different parse trees
does this sentence have? Compute the statistically best parse for this
sentence.
- (Optional extra credit) Consider the problems of part
of speech tagging and probabilistic parsing using a Prolog program that implements
the grammar and lexicon discussed here. What would be needed in the
Prolog program to automatically calculate the part of speech taggings and
select the best one? What would be needed in the Prolog program to
automatically calculate the parse tree probabilities and select the best
one? Design such a program.
References
- Charniak, E., Statistical Language Learning, MIT Press (1993).
- Allen, J., Natural Language Understanding, Chapter 7.
- DeRose, S.J., "Grammatical category disambiguation by statistical
optimization," Computational Linguistics 14, 31-39 (1988).
- Jurafsky, D. and J. Martin, Speech and Language Processing,
Prentice-Hall (2000).